Data Orchestration
Data orchestration is an automated process that takes data from multiple storage locations and programmatically allows you to author, schedule, and monitor data pipelines. Data orchestration platforms create a perfectly in-tune orchestra of data management, giving you an opportunity to control the data, monitor systems, and acquire real-time insights. Orchestrators don’t require custom scripts, which takes a load of work off the IT teams’ shoulders
Benefits:
- Faster decision making
- Reduced room for error
- Increased visibility and enhanced data quality
Data Flow
Use more data from more sources, faster

Faster decision making
By automating each stage, data engineers and analysts have more time to perform and draw actionable insights, hastening the decision-making process.
Read More
Reduced room for error
A common pitfall associated with manual scheduling in the past was human-prone errors. Programming the entire data pipeline process eliminates the room for such errors.
Read More
Increased visibility and enhanced data quality
Data orchestration helps break down data silos and makes data more available and accessible for analytics. Also, because each step in the data orchestration process executes in a streamlined manner and catches errors at each stage, companies can trust the quality of their data.
Read More
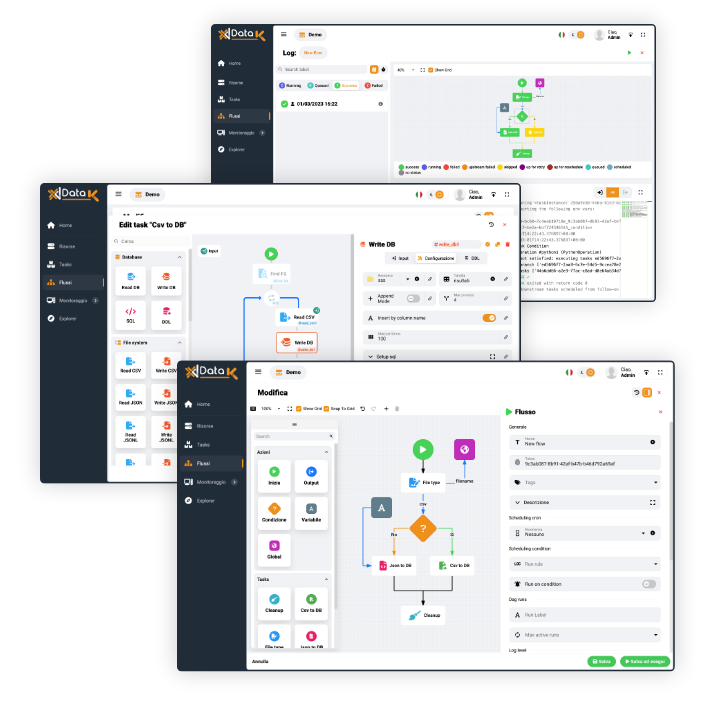
Orchestration: integrate anything and automate everything with only a unified platform. No-code data orchestration is facilitated by an intuitive graphical tool used to design data movement, transformation and flow orchestration.
Featuring a powerful user interface for creating and debugging data flows, it also provides a high-performance execution engine employed wherever data movement and orchestration are needed.

Monitoring & Logs
Flow: diagnostic panel with a complete view of downstream jobs and datasets, used for alerting users to assess the impact across the entire data ecosystem and taking steps to ensure that they are carried out with minimal risk.
Database process: See what’s being blocked and what’s doing the blocking. Get help understanding your blocking hierarchy as well as the overall impact to your performance caused by database blocking.
Logs: tracking and storing data flow execution to ensure application availability and to assess the impact of state transformations on performance
